
Over the past decade, the world has witnessed an unprecedented surge in data generation. Every click, swipe, transaction, and interaction contributes to a rapidly expanding digital universe. From streaming platforms and e-commerce websites to healthcare systems and smart cities, data is being produced at a scale that traditional systems were never designed to handle.
This is where Big Data Management with DBMS becomes essential—and where the role of Database Management Systems (DBMS) evolves dramatically. While DBMS has long been the backbone of structured data storage and retrieval, modern requirements demand systems that can scale horizontally, process data in real time, and handle a wide variety of data formats.
This article takes a deep dive into how Big Data and DBMS intersect, how technologies have evolved, and how you can understand and apply these concepts in real-world scenarios.
Understanding Big Data Beyond the Basics
Big Data is not just about size; it is about complexity and speed. The defining characteristics are often described using the 5 Vs, but understanding them deeply reveals why traditional systems fall short.
Volume refers to the sheer magnitude of data generated daily, often measured in terabytes or petabytes. Velocity captures the speed at which data is created and must be processed—think of real-time stock trading or live social media feeds. Variety highlights the diversity of data formats, from structured tables to images, videos, and logs. Veracity addresses the uncertainty and inconsistency that can exist within datasets, and Value focuses on the ultimate goal: extracting meaningful insights that drive decisions.
Big Data sources are everywhere—IoT sensors in smart homes, GPS signals from mobile devices, transaction records in banking systems, and user-generated content on social platforms. The challenge is not just storing this data, but processing and analyzing it efficiently.

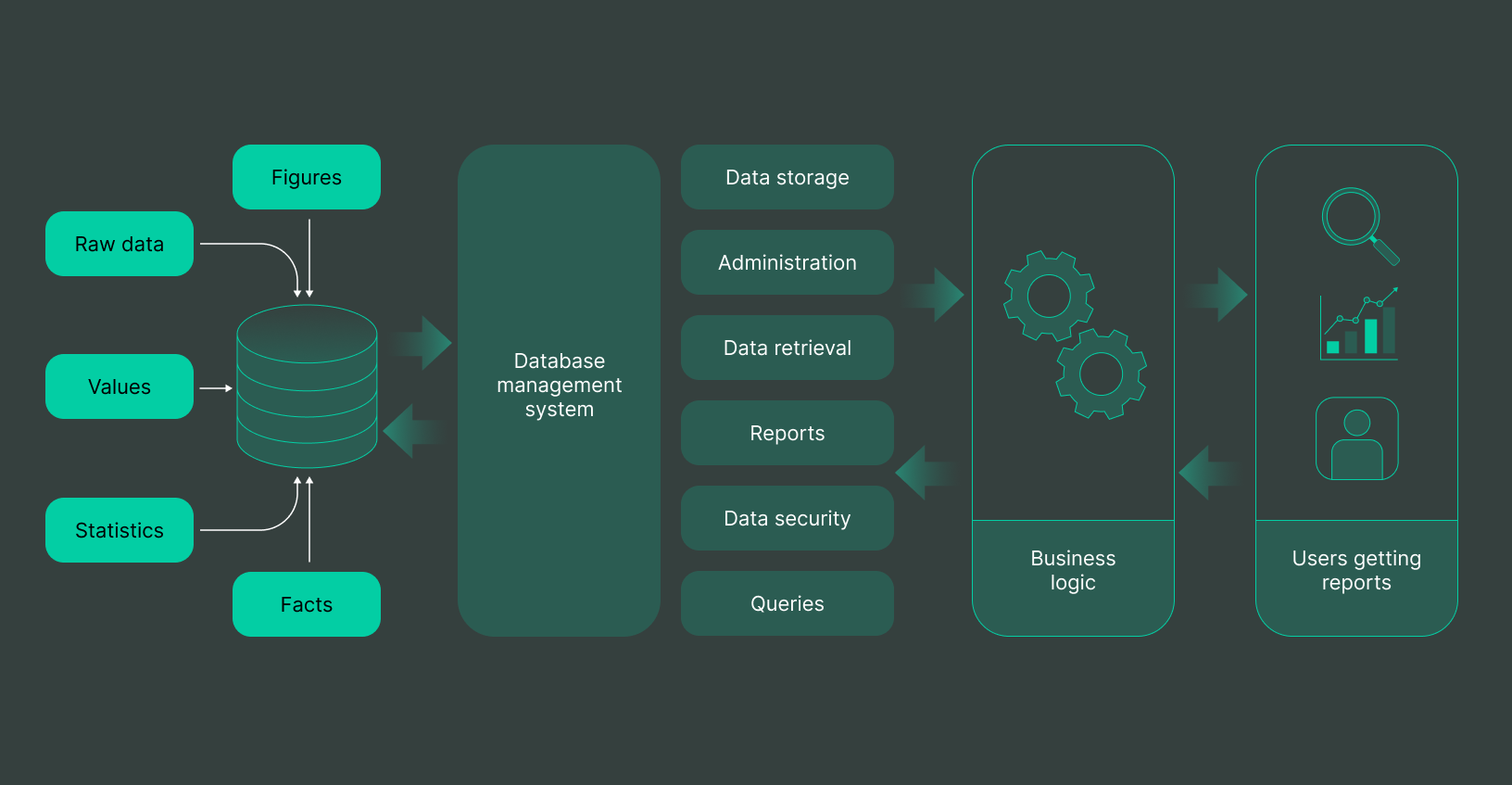
The Foundation: What DBMS Brings to the Table
A Database Management System (DBMS) is designed to organize, store, and retrieve data efficiently while maintaining consistency and security. Traditional DBMS, particularly relational database systems (RDBMS), rely on structured schemas and tables.
Systems like MySQL, PostgreSQL, Oracle, and SQL Server have powered enterprise applications for decades. They excel at handling structured data and enforcing rules such as ACID (Atomicity, Consistency, Isolation, Durability), which ensure reliable transactions.
However, as data grew in scale and diversity, limitations began to surface. Rigid schemas made it difficult to adapt to changing data formats, and scaling required expensive hardware upgrades rather than flexible distributed solutions.
Why Traditional DBMS Alone Is Not Enough
Traditional DBMS systems were built for a different era—one where data was predictable, structured, and relatively small in scale. As organizations began dealing with massive, fast-moving datasets, several challenges became evident.
Scaling a traditional database vertically—by adding more CPU, RAM, or storage—eventually reaches a limit and becomes cost-prohibitive. Performance bottlenecks arise when handling millions of concurrent queries or real-time data streams. Additionally, the structured nature of relational databases makes it difficult to accommodate unstructured or semi-structured data like JSON, logs, or multimedia content.
These challenges led to the development of new paradigms that complement or extend traditional DBMS capabilities rather than replacing them entirely.
The Shift Toward Big Data Ecosystems
Modern Big Data management is not built around a single system but rather a combination of technologies working together. This ecosystem approach allows organizations to handle different types of workloads efficiently.
NoSQL databases emerged as a flexible alternative to relational systems. They allow dynamic schemas and are optimized for specific use cases such as document storage, key-value access, or graph relationships. Distributed databases introduced the concept of spreading data across multiple machines, ensuring high availability and fault tolerance. Data lakes further expanded the landscape by enabling storage of raw data in its native format, ready for processing when needed.
This shift represents a move from monolithic database systems to modular, scalable architectures.
Architecture of Big Data Management Systems
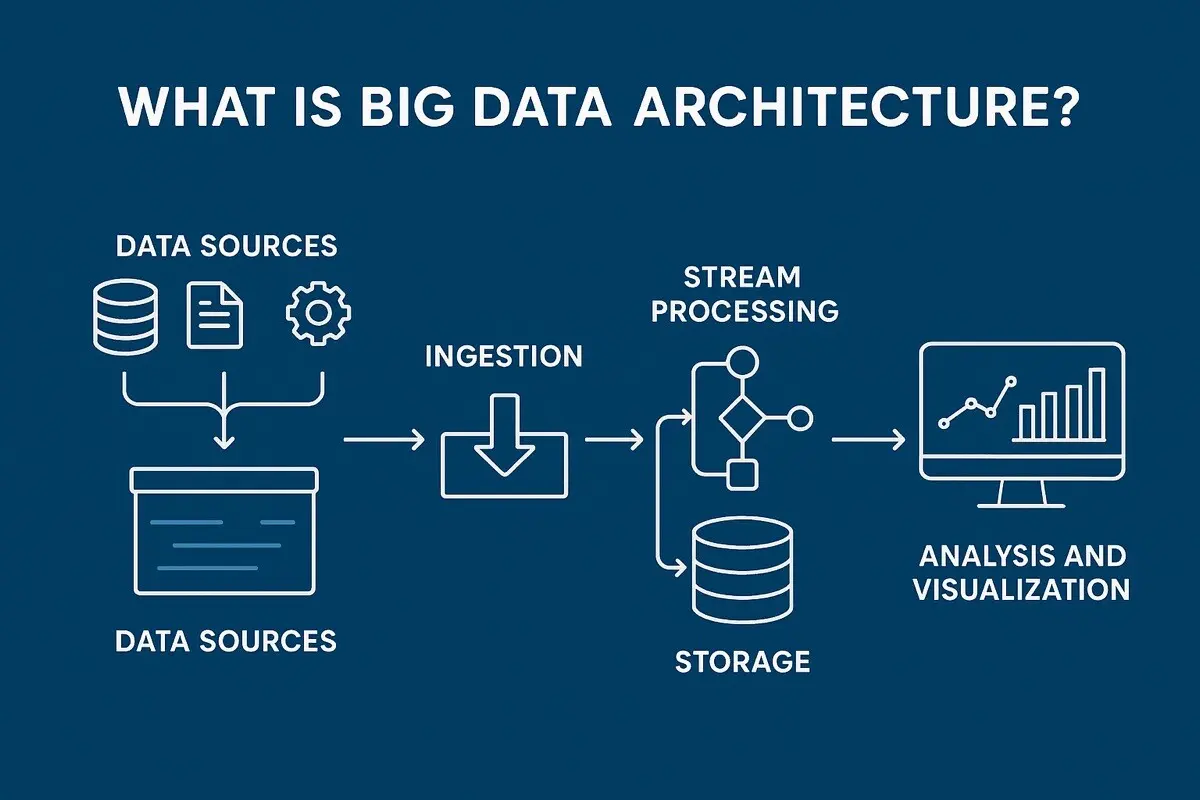
To truly understand how Big Data is managed, it is important to look at the architecture that supports it. Unlike traditional systems, Big Data architectures are layered and distributed.
At the entry point is the data ingestion layer, which collects data from various sources such as APIs, sensors, applications, and logs. This data may arrive in batches or as continuous streams.
The storage layer is designed to handle massive volumes of data. Distributed file systems and cloud storage solutions ensure that data is stored reliably across multiple nodes, reducing the risk of data loss.
The processing layer is where computation happens. Frameworks like Apache Spark and Hadoop MapReduce process data either in real time or in batches, depending on the use case.
Finally, the analytics layer transforms processed data into actionable insights. This includes dashboards, reports, and machine learning models that help organizations make informed decisions.
The Continuing Role of DBMS in Big Data
Despite the rise of new technologies, DBMS remains a critical component of Big Data management. It has not disappeared; rather, it has evolved.
Modern DBMS systems are now capable of integrating with distributed environments, supporting both structured and semi-structured data. They provide query optimization techniques that allow users to extract insights efficiently, even from large datasets. Transaction management remains crucial in applications where data consistency is non-negotiable, such as financial systems.
Security is another area where DBMS plays a vital role. With increasing concerns around data privacy, robust authentication, authorization, and encryption mechanisms are essential.
SQL and NoSQL: A Complementary Relationship
The debate between SQL and NoSQL is often misunderstood. In reality, both serve important purposes and are frequently used together in modern architectures.
SQL databases are ideal for structured data and complex queries, especially in systems requiring strong consistency. NoSQL databases, on the other hand, excel in handling large-scale, distributed, and flexible data structures.
Organizations often adopt a hybrid approach, using SQL systems for transactional workloads and NoSQL systems for high-speed, large-scale data processing. This combination provides both reliability and scalability.

Key Technologies Powering Big Data Management
The Big Data ecosystem includes several powerful tools and frameworks that work alongside DBMS.
Apache Hadoop introduced the concept of distributed storage and batch processing, enabling organizations to handle massive datasets across clusters of machines. Apache Spark improved upon this by offering faster, in-memory processing capabilities, making it suitable for real-time analytics.
Apache Hive provides a bridge between traditional SQL users and Big Data systems by allowing SQL-like queries on large datasets. Apache Kafka plays a crucial role in real-time data streaming, enabling systems to process continuous flows of data efficiently.
These technologies form the backbone of modern data architectures.
Challenges in Managing Big Data
While Big Data offers immense opportunities, it also introduces significant challenges. Integrating data from multiple sources can be complex, especially when formats and structures differ. Ensuring data quality is another major concern, as inaccurate or inconsistent data can lead to flawed insights.
Security and privacy have become critical issues, particularly with the increasing volume of sensitive data being stored and processed. Real-time processing requirements add another layer of complexity, as systems must deliver insights with minimal latency.
Additionally, there is a growing demand for skilled professionals who understand both traditional DBMS and modern Big Data technologies.
Best Practices for Effective Big Data Management
Managing Big Data effectively requires a strategic approach. Organizations must carefully choose the right combination of technologies based on their specific needs. Distributed systems should be leveraged for scalability, while proper data modeling techniques ensure efficient storage and retrieval.
Query optimization plays a significant role in improving performance, especially when dealing with large datasets. Data governance policies must be established to ensure compliance, security, and data integrity.
A hybrid architecture that combines SQL and NoSQL systems often provides the best balance between performance, flexibility, and reliability.
Real-World Applications Across Industries
Big Data management with DBMS is not just a theoretical concept—it is actively transforming industries.
In e-commerce, companies analyze user behavior to deliver personalized recommendations and optimize pricing strategies. In healthcare, large datasets are used for predictive analytics, improving diagnosis and treatment outcomes. Financial institutions rely on Big Data to detect fraud and manage risks in real time.
Social media platforms handle billions of interactions daily, using advanced data management systems to deliver seamless user experiences. Even smart cities leverage Big Data to optimize traffic flow, energy usage, and public services.
The Future of Big Data and DBMS

Looking ahead, the integration of Big Data and DBMS will continue to evolve. Cloud-native databases are becoming the standard, offering scalability and flexibility without the need for on-premise infrastructure. Artificial intelligence is being integrated into database systems to automate query optimization and data management tasks.
Serverless architectures are reducing operational complexity, allowing developers to focus on building applications rather than managing infrastructure. Concepts like data fabric and data mesh are redefining how data is organized and accessed across organizations.
The future promises systems that are not only more powerful but also more intelligent and easier to use.
Conclusion: Bridging Tradition and Innovation
Big Data Management with DBMS represents a convergence of traditional database principles and modern technological advancements. While the scale and complexity of data have increased dramatically, the core goal remains the same: to store, manage, and extract value from data efficiently.
By understanding how DBMS adapts to the demands of Big Data, you gain the ability to design systems that are both robust and scalable. Whether you are a student, developer, or data professional, mastering this domain is essential for staying relevant in the ever-evolving tech landscape.
Want to learn more ?, Kaashiv Infotech Offers, Data Science Course, Data Analytics Course, Power BI & More, Visit Our Website course.kaashivinfotech.com.
Related Reads:


