
History of Hadoop
The history of Hadoop architecture traces back to the early 2000s when Doug Cutting and Mike Cafarella developed an open-source search engine called Nutch. They faced difficulties managing massive datasets, which led to the idea of a distributed computing and storage system. In 2006, Hadoop was officially born under the Apache Software Foundation and was named after Cutting’s son’s toy elephant. This marked the beginning of what we now call the big data Hadoop architecture.
What is Hadoop Framework Architecture?
Hadoop framework architecture is an open-source, distributed computing model designed to store and process vast amounts of data across clusters of commodity hardware. It follows the MapReduce programming model and uses the Hadoop Distributed File System (HDFS) for efficient data storage. The architecture of Hadoop is renowned for its scalability, fault tolerance, and ability to handle structured, semi-structured, and unstructured data.
Key Components of Big Data Hadoop Architecture
Hadoop consists of several key components
HDFS (Hadoop Distributed File System)
HDFS is the primary storage system of Hadoop, designed to store large files across multiple machines in a distributed manner.
MapReduce
MapReduce is a programming model and processing engine for distributed data processing. It processes data in parallel across a Hadoop cluster.
YARN (Yet Another Resource Negotiator)
YARN is the resource management layer of Hadoop. It manages and allocates resources to applications running on the cluster, enabling multiple workloads to coexist.
Hadoop Architecture
The Hadoop architecture consists of the following components
HDFS

1.NameNode and DataNode
NameNode
It is the master server that manages the metadata and namespace of files and directories in HDFS.
DataNode
DataNodes are worker nodes that store the actual data blocks. They communicate with the NameNode to report data block status.
2. Block in HDFS
HDFS divides files into fixed-size blocks (typically 128MB or 256MB). These blocks are distributed across DataNodes in the cluster.
3. Replication Management
-HDFS replicates data blocks across multiple DataNodes to ensure fault tolerance. The default replication factor is 3, meaning each block is stored on three different DataNodes.
4.Rack Awareness
HDFS is rack-aware, meaning it takes into account the physical network topology to place replicas of data blocks on different racks for better fault tolerance and data locality.
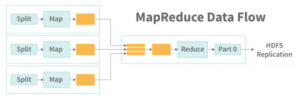
MapReduce

MapReduce is a two-stage processing framework where data is processed in parallel. The Map phase processes and filters data, and the Reduce phase aggregates and produces the final result.
YARN
YARN manages cluster resources and job scheduling. It consists of a ResourceManager (RM) for global resource management and NodeManagers (NMs) running on each node to monitor resource usage.
Advantages of Hadoop Architecture
Scalability
Hadoop can scale horizontally by adding more nodes to the cluster to handle growing data volumes.
Fault Tolerance
Hadoop ensures data durability and fault tolerance by replicating data across multiple nodes.
Cost-Effective
It runs on commodity hardware, reducing infrastructure costs.
Parallel Processing
Hadoop’s MapReduce framework enables parallel processing, speeding up data analysis.
Flexibility
Hadoop can process structured and unstructured data, making it suitable for a wide range of applications.
Disadvantages of Hadoop Architecture
Complexity
Setting up and managing a Hadoop cluster can be complex and requires skilled administrators.
Latency
Hadoop’s batch processing model may not be suitable for real-time or low-latency applications.
Programming Complexity
Writing MapReduce jobs can be challenging for developers.
Resource Intensive
Hadoop requires significant hardware resources, which can be expensive.
Data Security
Hadoop’s native security features have improved, but additional tools are often required for robust security.
Conclusion: Hadoop Architecture in Big Data
The Hadoop architecture has transformed how large-scale data is stored and processed. With components like HDFS, MapReduce, and YARN, the big data Hadoop architecture provides a reliable, scalable, and fault-tolerant environment for data analytics. Despite challenges like complexity and latency, Hadoop framework architecture remains foundational in big data ecosystems. As data continues to grow, Hadoop has evolved with technologies like Spark, Hive, and HBase, ensuring its relevance in the data-driven world.
FAQ’s
1.What is Hadoop Architecture?
Hadoop Architecture refers to the design and structure of the Hadoop ecosystem, which includes components like HDFS, MapReduce, and YARN, designed for distributed storage and processing of large datasets.
2.What is HDFS in Hadoop Architecture?
HDFS (Hadoop Distributed File System) is the primary storage component of Hadoop Architecture. It provides a distributed and fault-tolerant file system for storing large data across a cluster of commodity hardware.
3.What are NameNode and DataNode in HDFS?
NameNode is the master server in HDFS responsible for managing metadata and namespace. DataNode(s) are worker nodes that store the actual data blocks and communicate with the NameNode.
4.What is MapReduce in Hadoop Architecture?
MapReduce is a programming model and processing engine used in Hadoop for parallel data processing. It divides tasks into Map and Reduce phases, making it suitable for large-scale data analysis.
5.What is YARN in Hadoop Architecture?
YARN (Yet Another Resource Negotiator) is Hadoop’s resource management layer. It manages resource allocation and scheduling for applications running on the Hadoop cluster.


