Introduction
In the era of digital transformation, businesses and organizations are inundated with vast amounts of data from various sources. Harnessing the potential of this data requires a robust framework known as Big Data Architecture. This architecture provides a structured approach to collecting, storing, processing, and analyzing large volumes of data to extract valuable insights, make informed decisions, and gain a competitive edge. Efficient Freight Quotes are vital for logistics in industries handling big data, ensuring timely and cost-effective delivery of physical assets.
Table Of Content
- Introduction
- What is Big Data Architecture?
- Architecture of Big Data – Key Components
- 1. Data Sources
- 2. Data Ingestion Layer
- 3. Data Storage Layer
- 4. Data Processing Layer
- 5. Data Analytics & Visualization Layer
- 6. Data Orchestration & Workflow
- 7. Security & Governance
- Types of Big Data Architecture
- 1.Lambda Architecture
- 2.Kappa Architecture
- Big Data Tools and Techniques
- 1.Massively Parallel Processing (MPP)
- 2.No-SQL Databases
- 3.Distributed Storage and Processing Tools
- 4.Cloud Computing Tools
- Big Data Architecture Application
- E-commerce
- Healthcare
- Finance
- Manufacturing
- Social Media
- Benefits of Big Data Architecture
- Data-Driven Insights
- Scalability
- Real-time Processing
- Cost Efficiency
- Big Data Architecture Challenges
- Data Security
- Data Quality
- Scalability Complexity
- Integration
- Conclusion
What is Big Data Architecture?
Big Data Architecture is a comprehensive framework designed to handle the challenges posed by massive and diverse datasets. It encompasses various components and technologies that work together to manage, process, and analyze data efficiently. It serves as a blueprint for organizing data infrastructure, ensuring scalability, fault tolerance, and real-time processing.

Architecture of Big Data – Key Components
Let’s break down the essential building blocks of the architecture of big data:
1. Data Sources
These are the origin points where data is generated:
-
Social media feeds
-
IoT sensors
-
Logs and events
-
Transactional databases
-
APIs, mobile apps, CRM systems
2. Data Ingestion Layer
Responsible for collecting and importing data in real time or batch mode.
-
Tools: Apache Kafka, Apache Flume, Sqoop, NiFi
-
Function: Moves data from sources to processing layers
3. Data Storage Layer
Once ingested, data is stored for processing and analysis.
-
Data Lake (HDFS, Amazon S3) – for raw, unstructured data
-
Data Warehouse (Hive, BigQuery, Redshift) – for structured data
-
NoSQL Databases (MongoDB, Cassandra) – for semi-structured data
4. Data Processing Layer
This layer performs transformations, aggregations, and advanced analytics.
-
Batch Processing: Hadoop MapReduce, Apache Spark
-
Real-Time Processing: Apache Storm, Apache Flink, Spark Streaming
5. Data Analytics & Visualization Layer
This is where users interact with data and derive insights.
-
Analytics Tools: Apache Hive, Presto, Spark SQL
-
Visualization Tools: Tableau, Power BI, Kibana, Grafana
6. Data Orchestration & Workflow
Coordinates the flow and timing of jobs.
-
Tools: Apache Airflow, Oozie, Azkaban
7. Security & Governance
Ensures data privacy, compliance, and access control.
-
Authentication: Kerberos, LDAP
-
Authorization: Apache Ranger
-
Data Lineage: Apache Atlas
Types of Big Data Architecture
There are two prominent types of Big Data Architectures
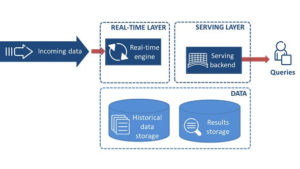
1.Lambda Architecture
Lambda Architecture combines batch processing and real-time streaming to handle Big Data. It maintains two separate layers: a batch layer for historical data processing and a speed layer for real-time data processing. The results from both layers are merged into a serving layer to provide a unified view of data.

2.Kappa Architecture
Kappa Architecture simplifies the complexities of Lambda Architecture by using a single stream-processing layer. It processes both historical and real-time data through a real-time stream processing engine, making it more streamlined and easier to manage.
Big Data Tools and Techniques
To implement Big Data Architecture effectively, several tools and techniques are employed
1.Massively Parallel Processing (MPP)
MPP databases distribute data processing tasks across multiple nodes or clusters, allowing for high-speed data processing and analytics.
2.No-SQL Databases
No-SQL databases, like MongoDB and Cassandra, are used for storing unstructured and semi-structured data, making them suitable for Big Data applications.
3.Distributed Storage and Processing Tools
Technologies like Hadoop HDFS and Apache Spark provide distributed storage and processing capabilities, enabling the handling of large datasets efficiently.
4.Cloud Computing Tools
Cloud platforms like AWS, Azure, and Google Cloud offer scalable and cost-effective infrastructure for Big Data processing and storage.
Big Data Architecture Application
Big Data Architecture finds application in various domains, including
E-commerce
Analyzing customer behavior, recommendations, and inventory management.
Healthcare
Processing electronic health records for predictive analytics and patient care.
Finance
Detecting fraud, risk assessment, and algorithmic trading.
Manufacturing
Optimizing supply chain, predictive maintenance, and quality control.
Social Media
Analyzing user sentiment, content recommendation, and trend analysis.
Benefits of Big Data Architecture
Data-Driven Insights
It enables organizations to derive valuable insights from their data, leading to informed decision-making.
Scalability
Big Data Architectures can scale horizontally, accommodating growing datasets and user demands.
Real-time Processing
It supports real-time data analysis, allowing businesses to respond promptly to changing conditions.
Cost Efficiency
Cloud-based solutions offer cost-effective infrastructure, reducing the need for extensive hardware investments.
Big Data Architecture Challenges
Data Security
Protecting sensitive data from breaches and unauthorized access.
Data Quality
Ensuring data accuracy and consistency for reliable analysis.
Scalability Complexity
Managing the complexity of scaling infrastructure to handle increasing data volumes.
Integration
Integrating data from diverse sources with different formats.
Conclusion
Big Data Architecture plays a pivotal role in modern data-driven organizations. It provides the structure and tools necessary to collect, process, and analyze vast datasets, unlocking valuable insights that drive innovation, efficiency, and competitiveness. While it comes with challenges, its benefits far outweigh the complexities, making it an indispensable component of the digital age. As data continues to grow, the evolution of Big Data Architecture will remain essential for harnessing its full potential.

