Data Warehouse Architecture Explained: Components, Types & Real-World Use Cases (2025 Guide)
Data Warehouse Architecture
Data warehouse architecture refers to the structure and design of a data warehouse system, which is a centralized repository for storing, managing, and analyzing large volumes of data from various sources. A well-designed data warehouse architecture ensures that data is organized, accessible, and optimized for business intelligence and data analytics purposes.
Table Of Content
- Data Warehouse Architecture
- Data Sources
- ETL (Extract, Transform, Load) Process
- Data Storage
- Star Schema
- Snowflake Schema
- Data Warehouse Layers
- Data Source Layer
- Data Transformation Layer
- Data Presentation Layer
- Data Warehouse Database Engine
- Metadata Repository
- Data Access and Query Tools
- Security and Access Control
- Data Quality and Governance
- Scalability and Performance
- Data Warehouse Architecture Properties
- Subject-Oriented
- Integrated
- Time-Variant
- Non-Volatile
- Scalable
- Performance-Optimized
- Multi-Tiered Architecture
- Data Modeling
- Metadata Management
- Security and Access Control
- Types of Data Warehouse Architectures
- 1.Single-Tier Architecture
- 2.Two-Tier Architecture
- Data Storage Tier
- Data Presentation Tier
- 3.Three-Tier Architecture
- Data Source Tier
- Data Integration Tier
- Data Presentation Tier
- Advantages of Data Warehouse Architecture
- Centralized Data Repository
- Subject-Oriented
- Historical Data Storage
- Improved Data Quality
- Optimized for Query Performance
- Disadvantages of Data Warehouse Architecture
- Complexity
- High Implementation Costs
- Data Latency
- Scalability Challenges
- Data Redundancy
- Conclusion: Understanding the Architecture of Data Warehouse in Practice
- FAQs: Common Questions About Data Warehousing Architecture
- 📚 Related Reads
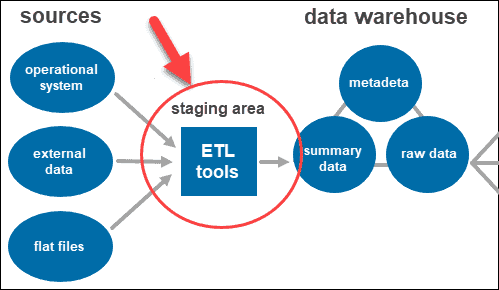
Data Sources
Data warehouses collect data from diverse sources, including databases, external systems, spreadsheets, and more. These sources may include operational databases, cloud-based applications, data lakes, and flat files.
ETL (Extract, Transform, Load) Process
ETL is a critical component that extracts data from source systems, transforms it into a consistent format, and loads it into the data warehouse. Transformation involves data cleaning, validation, aggregation, and formatting.
Data Storage
Data warehouses typically use a schema-based storage structure. There are two common schema designs:
Star Schema
Central fact tables that contain metrics surrounded by dimension tables that provide context.
Snowflake Schema
A variation of the star schema with normalized dimension tables.
Data Warehouse Layers
Data warehouses often consist of three primary layers
Data Source Layer
Contains the raw data extracted from source systems.
Data Transformation Layer
Where data is cleaned, transformed, and integrated.
Data Presentation Layer
Provides a structured view of data for reporting and analytics.
Data Warehouse Database Engine
The database engine is responsible for managing data storage, querying, and optimization. Commonly used databases for data warehousing include Oracle, Microsoft SQL Server, Teradata, and cloud-based solutions like Amazon Redshift and Google BigQuery.
Metadata Repository
Metadata is data about data. A metadata repository stores information about the data warehouse, including data definitions, lineage, transformations, and data cataloging.
Data Access and Query Tools
End-users and data analysts interact with the data warehouse through various query and reporting tools, such as SQL, BI tools (e.g., Tableau, Power BI), and custom applications.
Security and Access Control
Data warehouses implement security measures to protect sensitive data, including authentication, authorization, encryption, and role-based access control.
Data Quality and Governance
Data quality processes are essential for ensuring the accuracy and reliability of data. Data governance policies and practices help maintain data consistency and compliance with regulations.
Scalability and Performance
Scalability considerations are vital to accommodate growing data volumes and user demands. Techniques like partitioning, indexing, and data compression enhance performance.
Data Warehouse Architecture Properties
Data warehouse architecture is characterized by several key properties that define its structure, functionality, and capabilities. These properties ensure that a data warehouse effectively stores, manages, and provides access to data for business intelligence and analytics.
Subject-Oriented
Data warehouses are subject-oriented, meaning they focus on specific business subjects or areas, such as sales, finance, or customer data. They are designed to support the analysis of data related to these subjects.
Integrated
Data integration is a fundamental property of data warehouses. They consolidate data from multiple sources, including databases, applications, and external systems, to provide a unified and coherent view of information.
Time-Variant
Data warehouses store historical data and support time-based analysis. This property allows users to examine data trends, changes, and historical patterns over time, making it suitable for trend analysis and forecasting.
Non-Volatile
Data in a data warehouse is typically non-volatile, meaning that once data is loaded into the warehouse, it is not modified or deleted. New data is added as historical snapshots, preserving a historical record.
Scalable
Data warehouse architectures are designed to be scalable, enabling organizations to expand their storage capacity and processing power as data volumes grow. Scalability is critical to accommodate increasing data demands.
Performance-Optimized
Data warehouse systems are optimized for query performance. They use indexing, partitioning, caching, and optimization techniques to ensure that queries and reports run efficiently, even on large datasets.
Multi-Tiered Architecture
Data warehouses often have a multi-tiered architecture consisting of three primary layer.
the data source layer, the data transformation layer, and the data presentation layer. Each layer serves a specific purpose in data processing and reporting.
Data Modeling
Data warehouses use specialized data modeling techniques, such as star schema or snowflake schema, to structure data for efficient querying and reporting. These models involve fact tables (containing metrics) and dimension tables (providing context).
Metadata Management
Effective metadata management is a crucial property. Metadata, which includes data definitions, lineage, transformations, and data cataloging, helps users understand and navigate the data stored in the warehouse.
Security and Access Control
Data warehouses implement robust security measures to protect sensitive data. This includes authentication, authorization, encryption, and role-based access control to ensure data privacy and compliance.
Types of Data Warehouse Architectures
1.Single-Tier Architecture
In a single-tier data warehouse architecture, all the components, including data storage, ETL processes, and user interfaces, are combined into a single system or server. This architecture is the simplest but lacks scalability and flexibility. It is suitable for small-scale data warehousing needs where data volumes and complexity are limited. However, it may not be suitable for handling large and complex data environments.

2.Two-Tier Architecture
Two-tier data warehouse architecture separates the data storage and data presentation layers into two distinct tiers or components. The components are as follows
Data Storage Tier
This tier is responsible for storing and managing the data warehouse’s data. It includes the database engine, where data is stored in tables with defined schemas. The data is often structured for efficient querying and reporting.
Data Presentation Tier
- This tier is where end-users access the data and perform queries, reporting, and analysis. Business intelligence tools and reporting applications are typically part of this layer. The presentation tier communicates with the data storage tier to retrieve and display data.
- Two-tier architecture provides a level of separation between data storage and presentation, making it more scalable and suitable for medium to large-scale data warehousing requirements. However, it may still face limitations in terms of scalability and flexibility as data volumes grow.

3.Three-Tier Architecture
Three-tier data warehouse architecture further separates the components into three tiers, providing a more flexible and scalable design. The three components or tiers are as follows
Data Source Tier
This tier represents the source systems and data repositories where raw data originates. It includes various data sources such as databases, applications, and external systems.
Data Integration Tier
The data integration tier, often referred to as the ETL (Extract, Transform, Load) layer, is responsible for extracting data from source systems, transforming it into a suitable format, and loading it into the data warehouse’s data storage tier. Data cleansing, validation, and integration processes occur in this tier.
Data Presentation Tier
- Similar to the two-tier architecture, the data presentation tier is where end-users access and interact with the data using BI tools, reporting applications, and analytics platforms. It communicates with the data storage tier to retrieve and present data.
- Three-tier architecture provides greater flexibility, scalability, and maintainability, making it suitable for large-scale enterprise data warehousing solutions. It separates the data integration processes from data storage and data presentation, allowing for efficient data management and analysis.

Advantages of Data Warehouse Architecture
Data warehouse architecture offers several advantages that make it a critical component of modern data management and analytics. These advantages are instrumental in helping organizations efficiently store, manage, and analyze data for decision-making and business intelligence.
Centralized Data Repository
Data warehouses provide a centralized repository where data from multiple sources is consolidated and stored in a structured format. This centralization streamlines data access and ensures data consistency.
Subject-Oriented
Data warehouses are designed to be subject-oriented, allowing organizations to focus on specific business areas or subjects for analysis. This facilitates more meaningful and relevant insights.
Historical Data Storage
Data warehouses store historical data, enabling organizations to track and analyze trends and changes over time. This historical perspective is invaluable for making informed decisions and forecasting.
Improved Data Quality
Data quality is a priority in data warehouses. ETL processes include data cleaning, validation, and transformation, resulting in improved data accuracy and reliability.
Optimized for Query Performance
Data warehouses are optimized for query performance. Techniques such as indexing, partitioning, and caching ensure that queries and reports run efficiently, even on large datasets.
Disadvantages of Data Warehouse Architecture
While data warehouse architecture offers many advantages, it also has certain disadvantages and challenges that organizations should be aware of. These disadvantages can affect implementation, maintenance, and cost considerations.
Complexity
Building and maintaining a data warehouse can be a complex and resource-intensive process. Data integration, ETL (Extract, Transform, Load) processes, and data modeling require specialized skills and expertise.
High Implementation Costs
Implementing a data warehouse, especially in a large organization, can be expensive. Costs may include hardware, software, licensing, data integration tools, and skilled personnel.
Data Latency
Data warehouses may have latency in data updates. The process of extracting, transforming, and loading data can introduce delays, making real-time data analysis challenging.
Scalability Challenges
Scaling a data warehouse to accommodate growing data volumes and user demands can be complex and costly. Organizations may need to invest in hardware upgrades or cloud-based solutions.
Data Redundancy
Data redundancy can occur when data is replicated from source systems to the data warehouse. While this redundancy can improve query performance, it can also lead to increased storage requirements.
Conclusion: Understanding the Architecture of Data Warehouse in Practice
- In conclusion, data warehouse architecture is a fundamental component of modern data management and analytics, offering numerous advantages for organizations seeking to harness the power of their data. By providing a centralized, subject-oriented, and historically aware repository of data, data warehouses enable businesses to make data-driven decisions, uncover insights, and gain a competitive edge. They offer benefits such as improved data quality, query performance, scalability, and support for complex analytics.
- However, data warehouse architecture also comes with certain disadvantages and challenges, including complexity, high implementation costs, data latency, and maintenance overhead. These drawbacks should be carefully considered when planning and implementing a data warehouse solution.
1.What is data warehouse architecture?
Data warehouse architecture refers to the structured design and organization of a data warehouse system. It encompasses the layout, components, and processes involved in storing, managing, and accessing data for analytical purposes. It defines how data is collected, transformed, stored, and presented to end-users.
2.What are the key components of data warehouse architecture?
The key components of data warehouse architecture typically include data sources, ETL (Extract, Transform, Load) processes, data storage, metadata repositories, data access tools, security measures, and scalability features. These components work together to enable data integration, analysis, and reporting.
3.What are the benefits of using a data warehouse architecture?
Data warehouse architecture offers benefits such as centralized data storage, historical data tracking, improved data quality, optimized query performance, support for complex analytics, and data-driven decision-making. It provides a structured and efficient environment for managing and analyzing data.
4.What are the different types of data warehouse architectures?
Data warehouse architectures can be categorized into single-tier, two-tier, and three-tier architectures. Single-tier combines all components into one system, two-tier separates data storage from data presentation, and three-tier adds a data integration layer for ETL processes.
5.How does data warehousing support time-based analysis?
Data warehouses are time-variant, meaning they store historical data snapshots. This allows organizations to analyze data trends, changes, and historical patterns over time, supporting time-based analysis and trend forecasting.
")
")