
Data science has rapidly evolved into one of the most influential fields of the modern digital era. From personalized recommendations on streaming platforms to predictive healthcare and intelligent financial systems, data science sits at the heart of innovation. Yet, despite the explosion of tools, frameworks, and automation platforms, the true power of data science lies in understanding its foundational concepts.
Many beginners jump straight into coding, machine learning libraries, or dashboards without fully grasping the underlying principles. This often leads to shallow knowledge and poor decision-making. To become a strong data scientist in 2026 and beyond, you must develop a deep understanding of the core building blocks that drive the entire process.
This article explores 5 Foundational Concepts of Data Science that form the backbone of data science. These are not just steps in a workflow—they are skills that define how you think, analyze, and communicate with data.
5 Foundational Concepts of Data Science
1. Data Collection: Where Everything Begins
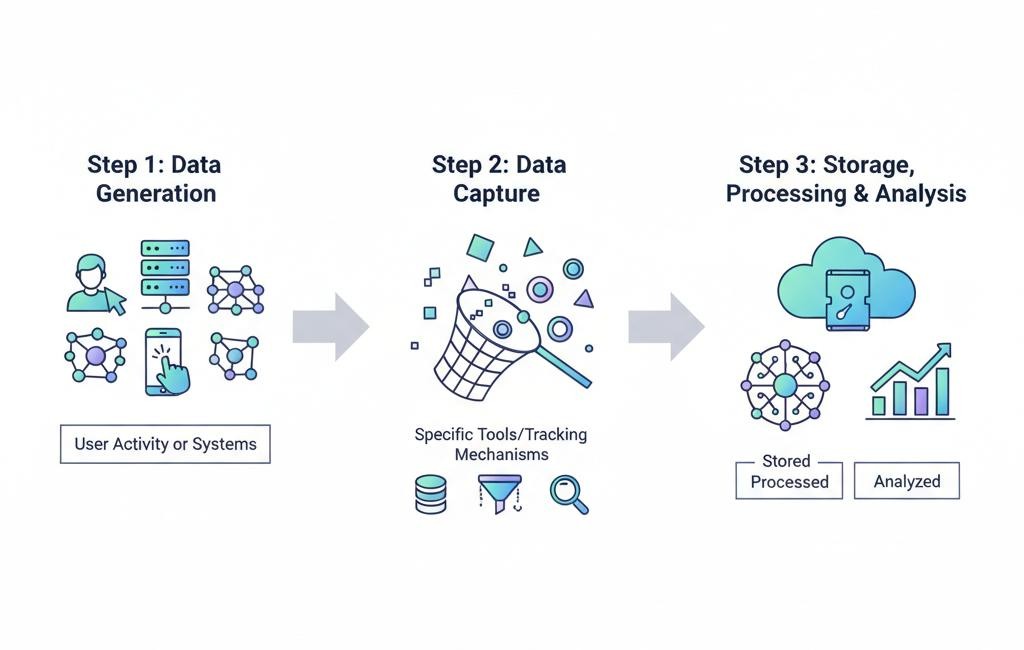
Every meaningful data science project starts with data collection. Without data, there is no analysis, no prediction, and ultimately, no value. But collecting data is not simply about gathering large volumes of information—it’s about gathering the right data.
In today’s connected world, data flows in from countless sources. Mobile applications track user behavior, websites log interactions, sensors capture environmental changes, and APIs provide access to external datasets. Organizations often rely on complex data pipelines to ingest and store this information in real time.
However, one of the biggest mistakes beginners make is assuming more data automatically leads to better results. In reality, irrelevant or biased data can completely distort outcomes. For example, if a dataset used for training a hiring algorithm lacks diversity, the model may produce biased recommendations.
Good data collection requires thoughtful questioning. You must understand the purpose of your project and ensure that the data aligns with your objectives. It also involves ethical considerations—privacy, consent, and responsible usage are more important than ever in 2026.
In essence, data collection is not just a technical task; it is a strategic decision-making process that determines the quality of everything that follows.
2. Data Cleaning: The Hidden Backbone of Data Science

Once data is collected, the next challenge emerges—making it usable. Raw data is rarely clean. It is often filled with inconsistencies, missing values, duplicate entries, and formatting issues that can break analysis or mislead models.
Data cleaning, also known as preprocessing, is the process of transforming raw data into a structured and reliable format. This stage is often underestimated, yet it consumes the majority of a data scientist’s time in real-world projects.
Imagine working with a dataset where dates appear in multiple formats, numerical values are stored as text, and several records are duplicated. If you skip cleaning and proceed to analysis, your results will be flawed, no matter how advanced your algorithms are.
Cleaning involves carefully examining the dataset, identifying issues, and applying corrections. This might include filling missing values, removing duplicates, standardizing units, or correcting errors. More importantly, it requires judgment—sometimes removing data can do more harm than good.
In many ways, data cleaning is where discipline meets patience. It may not be visually impressive, but it is the foundation upon which trustworthy insights are built.
3. Exploratory Data Analysis: Letting the Data Speak
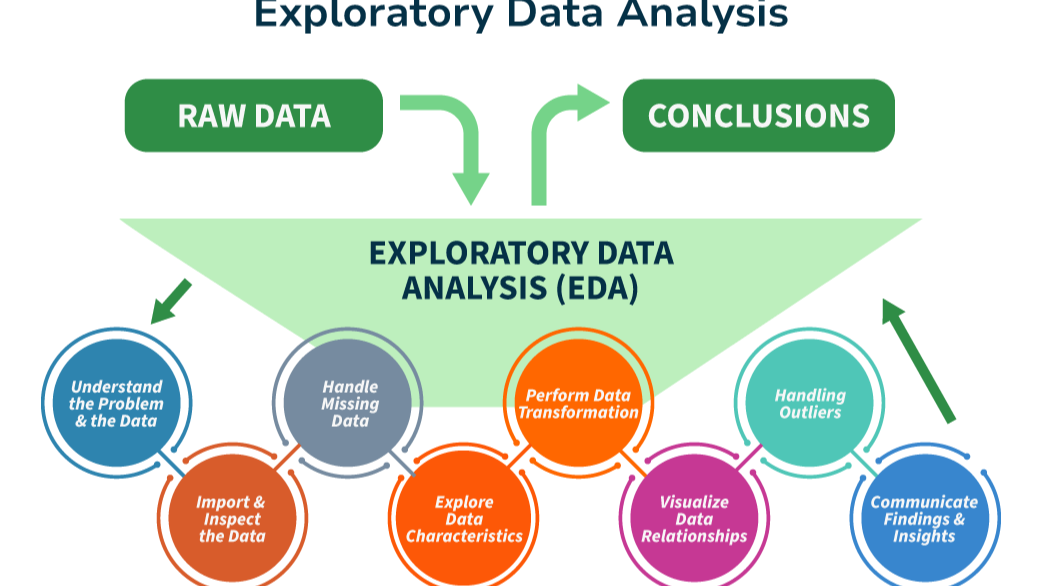
After cleaning the data, the next step is to understand it. Exploratory Data Analysis (EDA) is the phase where data scientists dive deep into the dataset to uncover patterns, relationships, and anomalies.
EDA is both analytical and intuitive. It involves summarizing data using statistics and visualizing it through charts and graphs. But beyond the tools, it is about curiosity—asking questions and seeking answers within the data.
For instance, you might explore how customer purchases vary over time, whether certain features are strongly correlated, or if there are unusual outliers that need attention. These insights often shape the direction of the entire project.
Visualization plays a critical role here. A well-designed chart can reveal trends that are impossible to detect in raw numbers. Patterns begin to emerge, and suddenly the dataset transforms from a collection of values into a meaningful story.
EDA is not about finding final answers—it is about forming hypotheses and building intuition. It prepares you for the next stage by helping you understand what kind of model or approach is appropriate.
4. Machine Learning: Transforming Data into Predictions
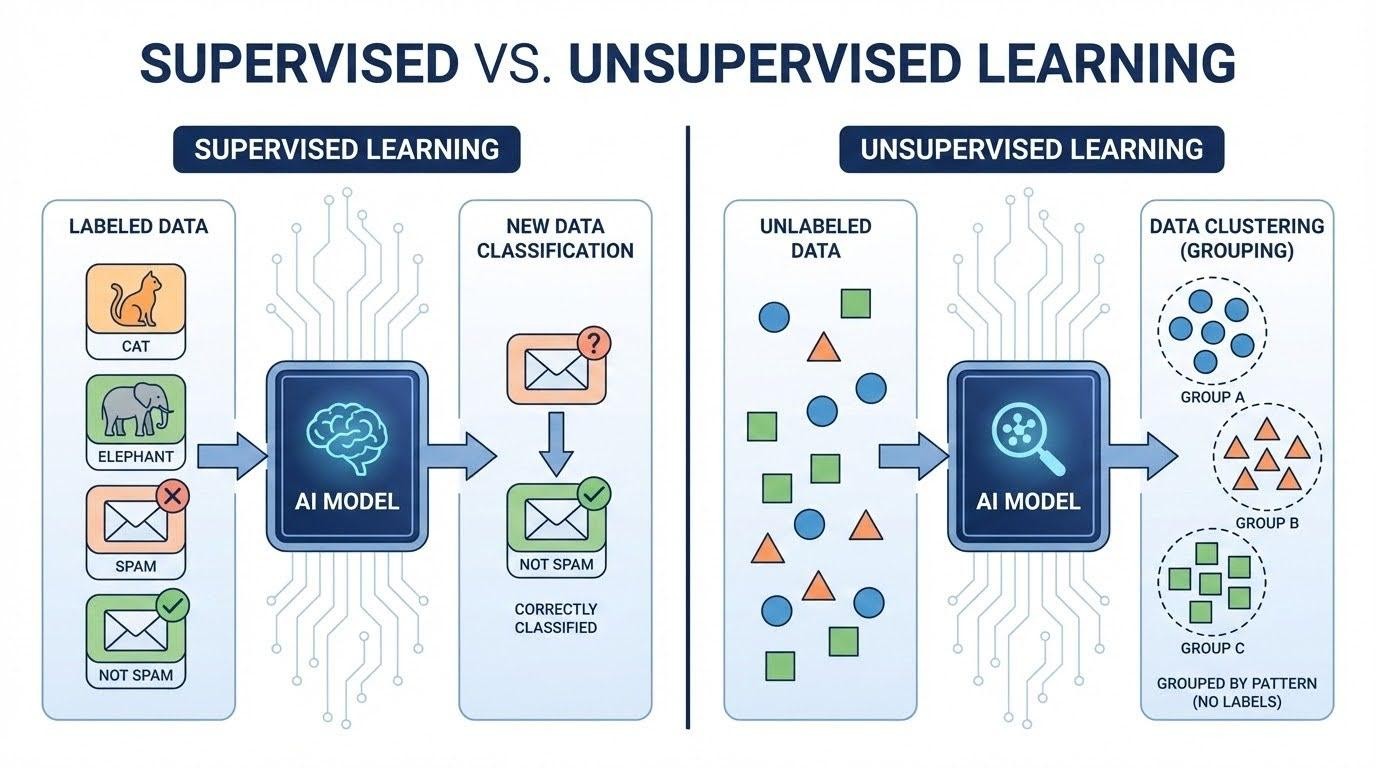
Machine learning is often seen as the most exciting part of data science, and for good reason. It allows systems to learn from data and make predictions without being explicitly programmed for every scenario.
At its core, machine learning involves feeding data into algorithms that identify patterns and use those patterns to make decisions. Depending on the problem, different types of learning are used. Supervised learning relies on labeled data, unsupervised learning uncovers hidden structures, and reinforcement learning focuses on decision-making through feedback.
Applications of machine learning are everywhere. Recommendation engines suggest what to watch or buy next, fraud detection systems identify suspicious transactions, and healthcare models assist in diagnosing diseases.
However, it is important to understand that machine learning is not magic. The quality of predictions depends heavily on the quality of data and the assumptions made during modeling. Overfitting, bias, and misinterpretation are common challenges that require careful handling.
A strong data scientist does not just build models—they understand when and why a model works, and when it should not be trusted.
5. Data Visualization and Communication: From Insight to Action

The final step in the data science journey is often the most overlooked—communication. No matter how advanced your analysis or how accurate your model, it has no impact unless others can understand and act on it.
Data visualization transforms complex results into clear and engaging visuals. Dashboards, charts, and reports allow stakeholders to quickly grasp insights and make informed decisions. But visualization alone is not enough; storytelling is equally important.
A good data scientist presents findings with context. They explain what was done, why it matters, and what actions should be taken. This requires the ability to translate technical results into simple, meaningful narratives.
In many organizations, the difference between a good and a great data scientist lies in communication skills. Those who can bridge the gap between data and decision-making become invaluable.
Why These Foundations Define Your Success
As tools become more automated and AI-driven platforms simplify workflows, it might seem like deep knowledge is less important. In reality, the opposite is true.
Automation can assist with execution, but it cannot replace critical thinking. Understanding these five concepts ensures that you are not blindly relying on tools but are making informed, intelligent decisions at every stage.
These foundations help you:
- Avoid common mistakes
- Build reliable models
- Interpret results accurately
- Communicate insights effectively
More importantly, they shape how you think about problems.
Final Thoughts
Data science is not just about coding or algorithms—it is about understanding data in a meaningful way. The journey from raw data to actionable insight is complex, but mastering these core concepts makes it manageable and rewarding.
When you focus on strong fundamentals, you gain the ability to adapt to any tool, any technology, and any future trend. Whether you are building predictive models, analyzing business performance, or creating AI-driven applications, these principles remain constant.
Learn them deeply, practice them consistently, and apply them thoughtfully. That is what transforms a beginner into a true data scientist.
ant to learn more ?, Kaashiv Infotech Offers, Data Science Course, Data Analytics Course, Power BI & More, Visit Our Website course.kaashivinfotech.com.


