In computer science, the tree data structure is one of the most powerful and widely used ways to organize data. Unlike linear structures such as arrays or linked lists, a tree represents data in a hierarchical form, much like a real-life tree or an organizational chart.
Table Of Content
- Understanding the Tree Structure
- Types of Tree Data Structures
- Binary Tree
- Binary Search Tree (BST)
- Self-Balancing Trees (AVL and Red-Black Trees)
- Heap
- B-Tree
- Trie (Prefix Tree)
- N-ary Tree
- Properties of Tree Data Structures
- Tree Traversal Techniques
- Applications of Tree Data Structures
- Advantages and Limitations
- Conclusion
- Related Reads
This structure is especially useful when data naturally forms relationships such as categories, subcategories, or dependencies. Whether you are working with file systems, search algorithms, or artificial intelligence models, trees play a foundational role.
At its core, a tree is made up of nodes connected by edges, where each node can point to one or more child nodes. The structure begins with a single node called the root, from which all other nodes branch out.
Understanding the Tree Structure
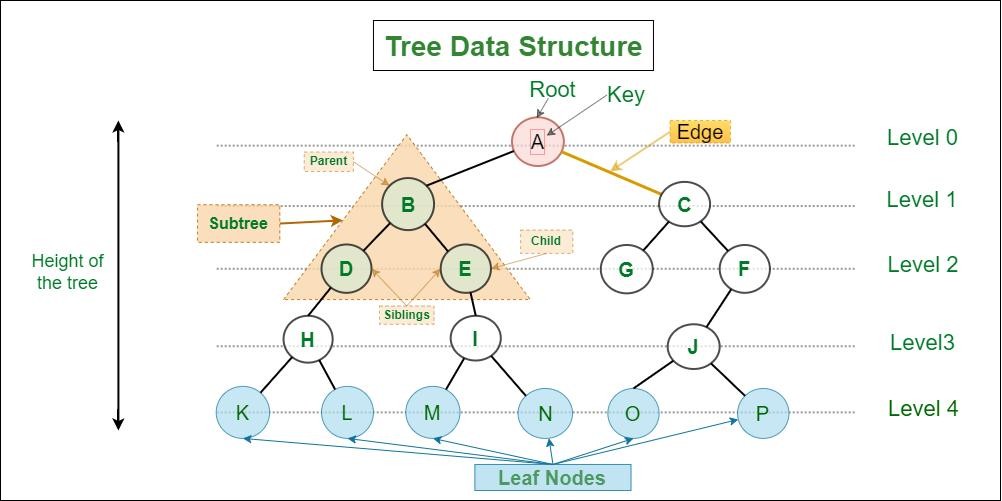
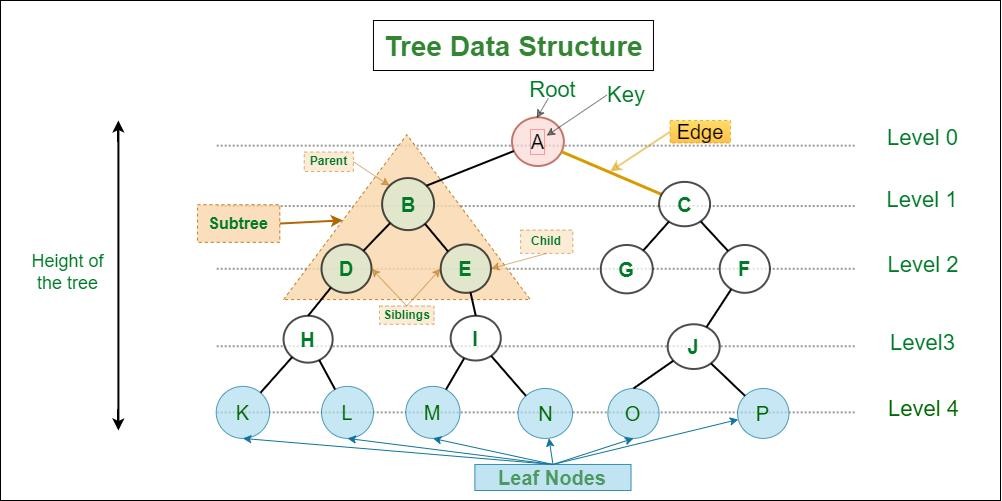
To fully grasp how trees work, it’s important to understand the basic components and relationships within them.
A node is the fundamental unit that holds data. Nodes are connected through edges, which represent relationships. The topmost node is called the root, and every node except the root has exactly one parent.
Nodes that do not have any children are known as leaf nodes, and these represent the endpoints of the structure. The concept of depth refers to how far a node is from the root, while the height of a tree measures the longest path from the root to any leaf node.
Another important concept is the subtree, which is simply any node along with all of its descendants. This recursive nature makes trees extremely flexible and powerful for solving complex problems.
Types of Tree Data Structures
Binary Tree
A binary tree is one of the simplest and most commonly used tree structures. In this type of tree, each node can have at most two children, typically referred to as the left child and the right child.
Binary trees can take several forms depending on how nodes are arranged. A full binary tree ensures that every node has either zero or two children. A complete binary tree fills all levels except possibly the last, and fills the last level from left to right. A perfect binary tree is completely filled, meaning all internal nodes have two children and all leaves are at the same level.
A balanced binary tree maintains a minimal height to ensure efficient operations, while a skewed tree behaves more like a linked list due to all nodes leaning to one side.
Binary Search Tree (BST)
A binary search tree introduces an ordering rule that significantly improves efficiency. For every node, values in the left subtree are smaller, and values in the right subtree are larger.
Because of this property, searching for an element becomes much faster compared to linear structures. In ideal conditions, operations such as search, insertion, and deletion can be performed in logarithmic time. However, if the tree becomes unbalanced, performance can degrade.
Self-Balancing Trees (AVL and Red-Black Trees)
To overcome the limitations of an unbalanced binary search tree, self-balancing trees were introduced.
An AVL tree maintains strict balance by ensuring that the height difference between left and right subtrees is never more than one. Whenever this condition is violated, rotations are performed to restore balance.
A Red-Black tree, on the other hand, uses a coloring system to maintain approximate balance. Each node is either red or black, and specific rules ensure that the tree remains balanced enough for efficient operations. These trees are widely used in real-world systems such as libraries and language runtimes.
Heap
A heap is a specialized binary tree primarily used in priority queues. It follows a specific ordering property rather than a strict structure like BSTs.
In a max heap, the parent node is always greater than or equal to its children, making the largest element easily accessible at the root. In a min heap, the smallest element is always at the root.
Heaps are commonly used in algorithms like heap sort and in scheduling systems where priority matters.
B-Tree
A B-Tree is designed for systems that handle large amounts of data, such as databases and file systems. Unlike binary trees, a B-Tree allows each node to have multiple children.
This structure reduces the height of the tree significantly, which in turn minimizes disk reads and improves performance. Because of these advantages, B-Trees are widely used in database indexing and storage engines.
Trie (Prefix Tree)
A trie is a unique tree structure used to store strings. Instead of storing complete words in nodes, each node represents a character.
This makes tries extremely efficient for operations like searching prefixes, autocomplete suggestions, and spell checking. For example, words like “cat,” “car,” and “cart” share common prefixes and can be efficiently stored in a trie.
N-ary Tree
An N-ary tree generalizes the concept of a tree by allowing each node to have more than two children. This structure is useful when modeling data that naturally has multiple branches, such as organizational hierarchies or XML/HTML documents.
Properties of Tree Data Structures
The mathematical and structural properties of trees help in analyzing their efficiency and behavior.
One fundamental property is that a tree with n nodes always has n−1 edges, which ensures there are no cycles. In binary trees, the number of nodes at a given level grows exponentially, which explains their efficiency in searching and sorting.
The height of a tree plays a crucial role in determining performance. A smaller height means faster operations. This is why balanced trees are preferred in most applications.
Another important property is the relationship between height and the maximum number of nodes. A binary tree of height h can contain up to 2h+1−12^{h+1} – 1 nodes, which shows how quickly trees can scale.
Understanding these properties helps developers design optimized algorithms and choose the right type of tree for specific tasks.
Tree Traversal Techniques
Traversal is the process of visiting all nodes in a tree in a systematic way. It is essential for accessing, modifying, or analyzing data stored in trees.
Depth-first traversal explores as far as possible along each branch before backtracking. This includes inorder traversal, which is particularly useful in binary search trees because it retrieves values in sorted order. Preorder traversal is often used to create copies of trees, while postorder traversal is useful for deleting or evaluating structures.
Breadth-first traversal, also known as level-order traversal, visits nodes level by level. This approach is particularly useful in applications like shortest path algorithms and network analysis.
Applications of Tree Data Structures
Tree data structures are deeply embedded in modern computing systems.
In operating systems, trees are used to represent file directories, where folders contain subfolders and files in a hierarchical manner. In databases, advanced tree structures like B-Trees make searching through massive datasets efficient and fast.
In web development, the Document Object Model (DOM) represents HTML and XML documents as trees, allowing browsers to render and manipulate content dynamically. In artificial intelligence, decision trees are used for classification and prediction tasks.
Compilers use syntax trees to understand and process programming languages, while networking systems rely on tree-based algorithms for routing and data transmission.
Advantages and Limitations
Trees provide a natural way to represent hierarchical relationships, making them intuitive and powerful. They enable efficient searching, insertion, and deletion operations when properly balanced. Their flexibility allows them to be used in a wide variety of applications, from simple data storage to complex machine learning models.
However, trees are not without challenges. Implementing and maintaining them can be complex, especially when balancing is required. They also consume more memory due to pointers and references. In cases where data does not have a hierarchical nature, simpler structures may be more efficient.
Conclusion
The tree data structure is a cornerstone of computer science, offering a versatile and efficient way to manage hierarchical data. From binary trees and search trees to advanced structures like tries and B-Trees, each type serves a unique purpose.
A strong understanding of tree data structure concepts, including their properties and traversal techniques, allows developers to solve problems more efficiently and design scalable systems. As technology continues to evolve, trees will remain an essential tool in building intelligent, high-performance applications.
Want to learn more ?, Kaashiv Infotech Offers, Data Science Course, Data Analytics Course, Power BI & More, Visit Our Website course.kaashivinfotech.com.
")
")